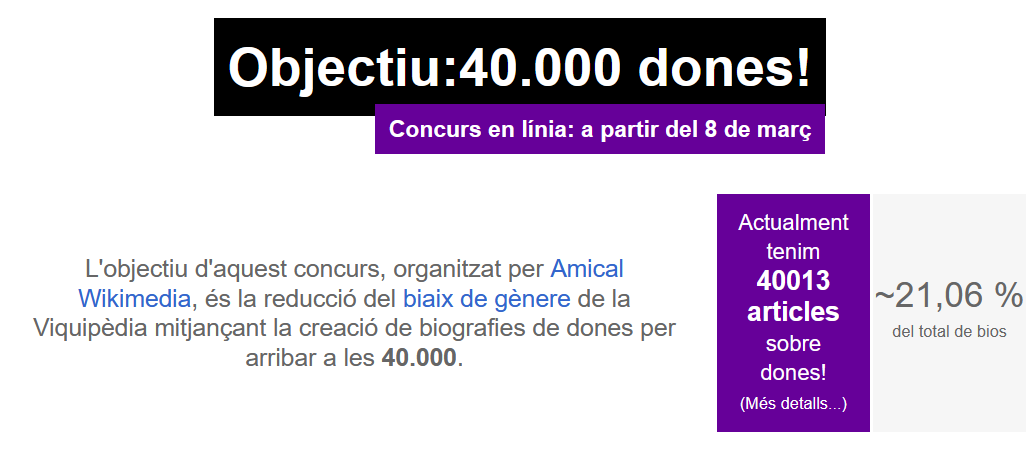
La Viquipèdia en català ha assolit l’objectiu d’arribar a les 40.000 biografies de dones en només un mes, des que el repte es va llençar, amb el nom de Viquiprojecte 40.000 Dones, coincidint amb el Dia Internacional de la Dona, el passat 8 de març. El divendres 5 d’abril, exactament quatre setmanes després de l’inici del projecte, es va tancar amb un total de 40.013 biografies de dones, el 21,06% del total. Això suposa haver afegit prop de 530 noves entrades referides a dones en aquest període.
La biografia que ha fet el número 40.000 ha estat la de l’editora i activista catalana Míriam Pey, publicada el 5 d’abril al migdia. Altres dones que ara tenen la seva entrada pròpia a la Viquipèdia són la cantant peruana Susana Baca, la política brasilera Manuela d’Ávila, l’actriu canadenca Cobie Smulders, la viròloga nord-americana Bernice Eddy, l’arquitecta i dissenyadora italiana Cini Boeri o Nancy Astor, primera dona a obtenir una acta de diputada a la Cambra dels Comuns britànica.
En aquesta fita hi han participat més de 30 viquipedistes, el que demostra la implicació de la comunitat amb la idea de disminuir el biaix de gènere existent a la Viquipèdia, també pel que fa als continguts.
El repte ha estat impulsat per Viquidones i Amical Wikimedia. En uns dies es farà públic el nom dels dos participants que han aconseguit una major puntuació en el repte (es valora la creació de nous articles però també l’aportació a d’altres ja existents), que rebran obsequis cortesia d’Amical.